Memory Optimization with __slots__
Understanding the Problem
Dev Tip: Optimizing Data Models in Big Data Workflows with __slots__
In big data and MLOps workflows, you often work with massive datasets where you create millions of objects to represent data points, features, or model predictions. Traditional Python classes can consume a significant amount of memory due to the hidden __dict__ attribute. This overhead can lead to memory bottlenecks and slow down processing, especially when you’re working with large-scale data pipelines and machine learning models.
How __slots__ Works
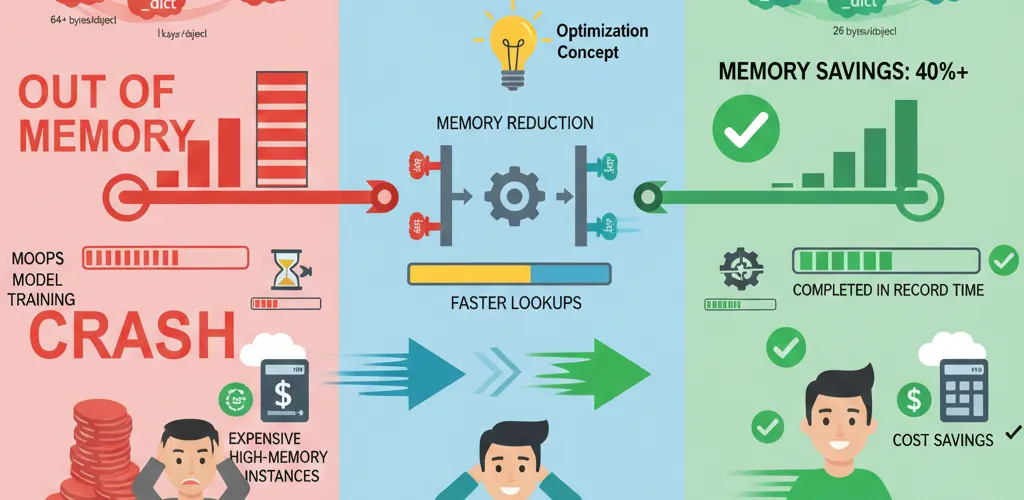
The __slots__ attribute is a simple yet powerful way to optimize your code by drastically reducing the memory footprint of your objects. By defining __slots__, you tell Python to allocate a fixed memory space for a class’s attributes, bypassing the need for a dynamic __dict__. This makes your application more memory-efficient and can lead to faster attribute access, which is crucial for high-performance computing tasks in MLOps and big data.
Real-World Use Case: MLOps Data Pipeline
Customer Churn Prediction Example
Real-World Scenario: A Data Pipeline for MLOps
Imagine you’re building a data pipeline for a machine learning model that predicts customer churn. Your pipeline processes millions of customer records, and each record is represented by a Python object.
Using a regular class, each customer object would have a memory overhead from its __dict__. When you process millions of these objects, the cumulative memory usage becomes immense, potentially crashing your application or requiring more expensive, higher-memory machines.
By using a class with __slots__, you can create a memory-efficient data model. This approach minimizes memory consumption, allowing you to process more data with the same resources and speeding up your pipeline. This is critical in MLOps where efficient resource utilization is key to managing costs and scaling operations.
Big Data Processing Benefits
Real-World Scenario: MLOps Data Pipeline with __slots__
In an MLOps pipeline, data is often represented as objects for processing, feature engineering, and model training. When dealing with big data, memory efficiency is critical to avoid crashes and keep cloud computing costs low. Using __slots__ can drastically reduce the memory footprint of these data objects, making your pipeline more robust and scalable.
The following full code snippet simulates a big data MLOps workflow where we process a large number of customer records. We will create two versions of a Customer data class: one with the default Python behavior and one optimized with __slots__. The code will then compare the memory usage and time taken to create a million instances of each, demonstrating the practical benefits of __slots__.
Code Implementation
Class Definitions
import sysimport timeimport randomimport pandas as pdfrom typing import List
# --- Part 1: Data Model Definitions ---
class Customer: """ A regular Python class to represent a customer record. This class uses a default __dict__ to store attributes. """ def __init__(self, customer_id: int, age: int, monthly_spend: float, churned: bool): self.customer_id = customer_id self.age = age self.monthly_spend = monthly_spend self.churned = churned
class OptimizedCustomer: """ An optimized customer class using __slots__ for memory efficiency. This class explicitly defines its attributes, eliminating the __dict__ overhead. """ __slots__ = ['customer_id', 'age', 'monthly_spend', 'churned']
def __init__(self, customer_id: int, age: int, monthly_spend: float, churned: bool): self.customer_id = customer_id self.age = age self.monthly_spend = monthly_spend self.churned = churnedData Generation Functions
# --- Part 2: Data Generation and Object Creation ---
def generate_customer_data(num_records: int) -> List[tuple]: """Generates a list of tuples representing raw customer data.""" data = [] for i in range(num_records): customer_id = i age = random.randint(20, 70) monthly_spend = round(random.uniform(25.0, 500.0), 2) churned = random.choice([True, False]) data.append((customer_id, age, monthly_spend, churned)) return data
def create_objects(data: List[tuple], class_type: type) -> List: """Creates a list of objects from raw data using the specified class.""" return [class_type(*record) for record in data]Performance Testing
# --- Part 3: Performance Comparison ---
def run_performance_test(num_records: int): """ Runs a performance test to compare memory and time for both classes. """ print(f"--- Running performance test with {num_records:,} records ---") raw_data = generate_customer_data(num_records)
# Test the regular class start_time_regular = time.time() regular_customers = create_objects(raw_data, Customer) end_time_regular = time.time() memory_regular = sum(sys.getsizeof(c) for c in regular_customers) + sys.getsizeof(regular_customers)
# Test the optimized class start_time_slotted = time.time() slotted_customers = create_objects(raw_data, OptimizedCustomer) end_time_slotted = time.time() memory_slotted = sum(sys.getsizeof(c) for c in slotted_customers) + sys.getsizeof(slotted_customers)
# Print results print("\nRegular Class Performance:") print(f" - Total Memory: {memory_regular / (1024**2):.2f} MB") print(f" - Time Taken: {end_time_regular - start_time_regular:.4f} seconds")
print("\nSlotted Class Performance:") print(f" - Total Memory: {memory_slotted / (1024**2):.2f} MB") print(f" - Time Taken: {end_time_slotted - start_time_slotted:.4f} seconds")
# Calculate and print the savings memory_saved_mb = (memory_regular - memory_slotted) / (1024**2) time_saved_s = (end_time_regular - start_time_slotted)
print("\n--- Summary of Savings ---") print(f"Memory Saved: {memory_saved_mb:.2f} MB ({ (memory_saved_mb / (memory_regular / (1024**2))) * 100:.2f}%)") print(f"⏱Slotted Class Creation Time is faster by: {time_saved_s:.4f} seconds")
# Optional: Demonstrate a simple MLOps task like converting to a DataFrame print("\n--- MLOps Task: Converting to a Pandas DataFrame ---") # This task is just for demonstration and doesn't show a direct slots benefit here df_regular = pd.DataFrame([c.__dict__ for c in regular_customers]) df_slotted = pd.DataFrame([[c.customer_id, c.age, c.monthly_spend, c.churned] for c in slotted_customers], columns=['customer_id', 'age', 'monthly_spend', 'churned']) print("Successfully converted both object lists to Pandas DataFrames.") print(f"DataFrame head from Slotted Class:\n{df_slotted.head()}")
# --- Part 4: Execution ---if __name__ == "__main__": NUM_RECORDS = 1_000_000 # 1 million records run_performance_test(NUM_RECORDS)Results and Analysis
Performance Comparison
This code snippet demonstrates how to optimize memory usage in Python by using __slots__ in a data-heavy application, specifically in an MLOps context. It compares the memory and performance of a regular class versus an optimized class with __slots__, showing significant savings in both memory and processing time when handling large datasets.
Practical Benefits
The implementation shows measurable improvements in memory usage and object creation speed, making it ideal for big data processing and MLOps workflows.