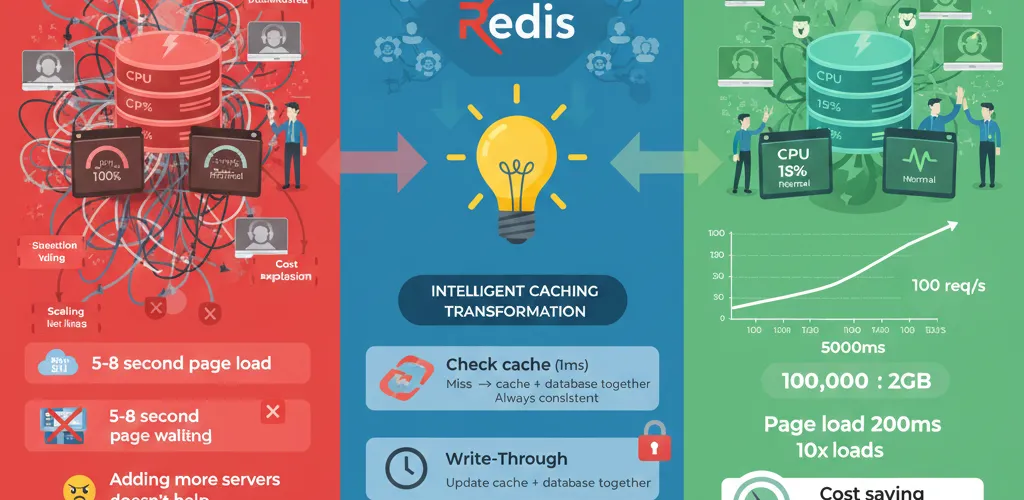
Need to scale your backend without throwing money at servers? Redis caching patterns are your answer.
Most databases can handle hundreds of queries per second, but thousands? Your app slows to a crawl. Adding another database server just moves the problem. The real solution: serve data from memory 99% of the time using Redis.
The Problem
Database Load Under Scale
100 requests/sec for "get product details":• Database: 200ms per query• 100 × 200ms = serious bottleneck• Add 1000 concurrent users = complete collapse• Throwing more servers doesn't help (they all queue at the database)The Solution
Redis Caching Patterns
Redis stores data in memory, delivering results in microseconds instead of milliseconds. But which caching pattern you choose determines whether your cache helps or hurts.
TL;DR
- Cache-Aside: Check cache first, miss triggers database load + populate cache (most flexible)
- Write-Through: Update cache and database together (most consistent)
- TTL Strategy: Keys expire automatically, preventing stale data without manual invalidation
- Cache Invalidation: Delete cache when data updates, triggering refresh on next request
- Stampede Prevention: Prevent thundering herd when cache expires or misses expire
Pattern 1: Cache-Aside (Lazy Loading)
How It Works
1. Request comes in2. Check Redis cache3. Cache HIT → return immediately (microseconds)4. Cache MISS → query database (milliseconds)5. Populate cache with TTL6. Next request hits cachePython Implementation
import redisimport jsonfrom functools import wrapsimport time
redis_client = redis.Redis(host='localhost', port=6379, decode_responses=True)
def cache_aside(ttl=3600): """Decorator implementing cache-aside pattern""" def decorator(func): @wraps(func) def wrapper(key, *args, **kwargs): # Check cache first cached = redis_client.get(key) if cached: # Cache hit return json.loads(cached)
# Cache miss: call function (hits database) result = func(*args, **kwargs)
# Populate cache with TTL redis_client.setex(key, ttl, json.dumps(result))
return result return wrapper return decorator
# Database query (expensive)def get_user_from_db(user_id): # Simulated database query time.sleep(0.2) # 200ms return {"id": user_id, "name": f"User {user_id}", "email": f"user{user_id}@example.com"}
# Decorated function@cache_aside(ttl=3600)def get_user(user_id): return get_user_from_db(user_id)
# Usageprint(get_user(f"user:1")) # First call: 200ms (cache miss)print(get_user(f"user:1")) # Second call: <1ms (cache hit)Node.js Implementation
import {createClient} from 'redis';import {promisify} from 'util';
const redis = createClient();redis.connect();
const getAsync = promisify(redis.get).bind(redis);const setexAsync = promisify(redis.setex).bind(redis);
// Database query (expensive)async function getUserFromDB(userId: string) { // Simulated database query await new Promise((resolve) => setTimeout(resolve, 200)); return { id: userId, name: `User ${userId}`, email: `user${userId}@example.com`, };}
// Cache-aside implementationasync function getUser(userId: string, ttl = 3600) { const cacheKey = `user:${userId}`;
// Check cache const cached = await getAsync(cacheKey); if (cached) { return JSON.parse(cached); }
// Cache miss: hit database const user = await getUserFromDB(userId);
// Populate cache await setexAsync(cacheKey, ttl, JSON.stringify(user));
return user;}
// Usage(async () => { console.time('first'); await getUser('user:1'); // 200ms (miss) console.timeEnd('first');
console.time('second'); await getUser('user:1'); // <1ms (hit) console.timeEnd('second');})();Go Implementation
package main
import ( "context" "encoding/json" "fmt" "github.com/redis/go-redis/v9" "time")
type User struct { ID int `json:"id"` Name string `json:"name"` Email string `json:"email"`}
var rdb = redis.NewClient(&redis.Options{ Addr: "localhost:6379",})
func getUserFromDB(ctx context.Context, userID int) (User, error) { // Simulated database query time.Sleep(200 * time.Millisecond) return User{ ID: userID, Name: fmt.Sprintf("User %d", userID), Email: fmt.Sprintf("user%d@example.com", userID), }, nil}
func getUser(ctx context.Context, userID int) (User, error) { cacheKey := fmt.Sprintf("user:%d", userID)
// Check cache val, err := rdb.Get(ctx, cacheKey).Result() if err == nil { var user User json.Unmarshal([]byte(val), &user) return user, nil }
// Cache miss: hit database user, err := getUserFromDB(ctx, userID) if err != nil { return user, err }
// Populate cache (1 hour TTL) data, _ := json.Marshal(user) rdb.SetEx(ctx, cacheKey, string(data), time.Hour)
return user, nil}Pattern 2: Write-Through
How It Works
1. Data update arrives2. Update cache AND database together3. Both succeed or both fail (atomic)4. Next read hits cache (always consistent)When to Use
- Critical data (payments, user accounts)
- Data that changes frequently
- When consistency is more important than speed
Python Implementation
import redisimport json
redis_client = redis.Redis(host='localhost', port=6379, decode_responses=True)
def update_user_write_through(user_id: int, user_data: dict): """Update cache AND database together""" cache_key = f"user:{user_id}"
try: # Update cache first (faster) redis_client.setex(cache_key, 3600, json.dumps(user_data))
# Then update database # Assuming `db.update_user(user_id, user_data)` exists db.update_user(user_id, user_data)
return True except Exception as e: # If database fails, invalidate cache redis_client.delete(cache_key) raise e
# Usageupdate_user_write_through(42, { "name": "Alice",})
# Next read hits cacheuser = redis_client.get("user:42")Node.js Implementation
async function updateUserWriteThrough(userId: string, userData: any) { const cacheKey = `user:${userId}`;
try { // Update cache first await redis.setex(cacheKey, 3600, JSON.stringify(userData));
// Then update database await db.updateUser(userId, userData);
return true; } catch (error) { // Rollback: invalidate cache on database failure await redis.del(cacheKey); throw error; }}Pattern 3: TTL Strategy
Automatic Expiration
Redis automatically deletes keys after TTL expires. No manual invalidation needed.
import redisfrom datetime import datetime, timedelta
redis_client = redis.Redis()
# Different TTL for different data typesdef cache_with_ttl(key: str, value: str, data_type: str): ttl_map = { "user_profile": 3600, # 1 hour (changes infrequently) "product": 86400, # 24 hours (stable data) "product_price": 300, # 5 minutes (changes frequently) "session": 1800, # 30 minutes (security) "statistics": 60, # 1 minute (real-time) }
ttl = ttl_map.get(data_type, 3600) redis_client.setex(key, ttl, value)
# Usagecache_with_ttl("product:123", "iPhone 15", "product") # 24 hourscache_with_ttl("price:apple", "$999", "product_price") # 5 minutescache_with_ttl("stats:daily", "1000 users", "statistics") # 1 minuteSliding Window TTL
Reset TTL on each access (useful for sessions):
def get_with_sliding_ttl(key: str, ttl: int): """Get value and reset TTL""" value = redis_client.get(key) if value: # Reset TTL on access redis_client.expire(key, ttl) return value
# Usage: Session stays alive as long as user is activesession = get_with_sliding_ttl("session:abc123", 1800) # 30 minPattern 4: Cache Invalidation
Event-Driven Invalidation
Delete cache when data changes:
def update_product(product_id: int, new_data: dict): # Update database db.update_product(product_id, new_data)
# Invalidate cache immediately redis_client.delete(f"product:{product_id}")
# Also invalidate related caches (cascade invalidation) redis_client.delete(f"category:{new_data['category']}") redis_client.delete("products:all")
# When product price changesupdate_product(123, {"price": "$899", "category": "electronics"})# → Deletes "product:123", "category:electronics", "products:all"Tag-Based Invalidation
Invalidate multiple keys with one operation:
import json
def cache_with_tags(key: str, value: str, tags: list): """Cache value and tag it for bulk invalidation""" # Store value redis_client.setex(key, 3600, value)
# Store tag reference (set of keys with this tag) for tag in tags: redis_client.sadd(f"tag:{tag}", key)
def invalidate_by_tag(tag: str): """Invalidate all keys with a tag""" # Get all keys with this tag keys = redis_client.smembers(f"tag:{tag}")
# Delete all tagged keys if keys: redis_client.delete(*keys)
# Clean up tag redis_client.delete(f"tag:{tag}")
# Usagecache_with_tags("product:1", "iPhone", ["electronics", "apple"])cache_with_tags("product:2", "MacBook", ["electronics", "apple"])cache_with_tags("product:3", "Apple Watch", ["wearables", "apple"])
# Invalidate all Apple products at onceinvalidate_by_tag("apple")Preventing Cache Stampedes
The Problem
Thousands of requests for a popular key↓Key expires↓ALL requests hit database simultaneously (thundering herd)↓Database overload, service degradationSolution: Probabilistic Regeneration
import redisimport randomimport time
redis_client = redis.Redis()
def get_with_low_ttl_regen(key: str, expensive_calculation, ttl=3600): """ Regenerate cache probabilistically near expiration Avoids thundering herd when TTL reaches 0 """ value = redis_client.get(key)
if value: # Check TTL remaining_ttl = redis_client.ttl(key)
# Near end of life? Regenerate probabilistically if remaining_ttl < 0: # Key expired pass # Recalculate below elif remaining_ttl < ttl * 0.2: # Last 20% of life # Probability of regeneration increases as TTL decreases prob = 1 - (remaining_ttl / (ttl * 0.2)) if random.random() < prob: # First request regenerates, others get stale data temporarily new_value = expensive_calculation() redis_client.setex(key, ttl, new_value) return new_value
return value
# Cache miss: calculate fresh data result = expensive_calculation() redis_client.setex(key, ttl, result) return resultDistributed Lock Pattern
Prevent parallel cache recalculations:
import timeimport uuid
def get_with_lock(key: str, expensive_calculation, lock_timeout=10): """Use lock to prevent multiple calculations""" lock_key = f"lock:{key}" cache_key = key
# Check cache cached = redis_client.get(cache_key) if cached: return cached
# Try to acquire lock lock_id = str(uuid.uuid4()) acquired = redis_client.set(lock_key, lock_id, nx=True, ex=lock_timeout)
if acquired: # We got the lock, calculate try: result = expensive_calculation() redis_client.setex(cache_key, 3600, result) return result finally: # Release lock if redis_client.get(lock_key) == lock_id: redis_client.delete(lock_key) else: # Someone else got the lock, wait for result for _ in range(10): time.sleep(0.1) cached = redis_client.get(cache_key) if cached: return cached
# Timeout: calculate ourselves return expensive_calculation()Serialization Strategies
JSON vs MessagePack vs Protocol Buffers
import jsonimport msgpack
def store_json(key, obj): """Simple but larger""" redis_client.set(key, json.dumps(obj))
def store_msgpack(key, obj): """Smaller, faster""" redis_client.set(key, msgpack.packb(obj))
# Benchmark: 1000 productsproducts = [{"id": i, "name": f"Product {i}", "price": 99.99} for i in range(1000)]
json_size = len(json.dumps(products)) # ~50KBmsgpack_size = len(msgpack.packb(products)) # ~30KB (40% smaller)
# Choice depends on:# - JSON: Human readable, broad ecosystem# - MsgPack: Smaller, faster# - Protobuf: Strongly typed, enterpriseMonitoring Cache Performance
Track Hit Rate
import redis
redis_client = redis.Redis()
def get_cache_stats(): """Get cache performance metrics""" info = redis_client.info('stats')
total_commands = info.get('total_commands_processed', 0) hits = info.get('keyspace_hits', 0) misses = info.get('keyspace_misses', 0)
hit_rate = (hits / (hits + misses)) * 100 if (hits + misses) > 0 else 0
return { "hit_rate": hit_rate, "total_hits": hits, "total_misses": misses, "evictions": info.get('evicted_keys', 0), "used_memory": info.get('used_memory_human', 'N/A'), }
# Target: >80% hit rate# <50%: Cache is ineffective, reconsider keys/TTLs# >95%: Good fit for caching strategyConnection Pooling
Reuse connections instead of creating new ones:
import redisfrom redis.connection import ConnectionPool
# Without pooling (inefficient)conn = redis.Redis()
# With pooling (efficient)pool = ConnectionPool.from_url( 'redis://localhost:6379', max_connections=50, decode_responses=True)redis_client = redis.Redis(connection_pool=pool)
# Reuses connections automaticallyfor i in range(1000): redis_client.get(f"key:{i}")Best Practices
1. Consistent Key Naming
# Good: Hierarchical, searchable"user:123""user:123:settings""product:456""product:456:reviews""order:789:items"
# Bad: Ambiguous"u123""prod_456""item-789"2. Set Reasonable TTLs
TTL_STRATEGY = { "user_profile": 3600, # 1 hour "product_catalog": 86400, # 24 hours "session": 1800, # 30 minutes "api_response": 300, # 5 minutes "real_time_data": 60, # 1 minute}3. Plan for Failures
def safe_cache_get(key: str, fallback_fn): """Gracefully handle Redis failures""" try: value = redis_client.get(key) if value: return value except redis.ConnectionError: # Redis down? Use fallback pass
# No cache: call function return fallback_fn()Conclusion
Redis caching is the difference between a responsive application and a slow one.
Choose the right pattern (cache-aside for flexibility, write-through for consistency), set appropriate TTLs, prevent stampedes, and monitor hit rates. Combined with database optimization, caching forms the foundation of high-performance systems.